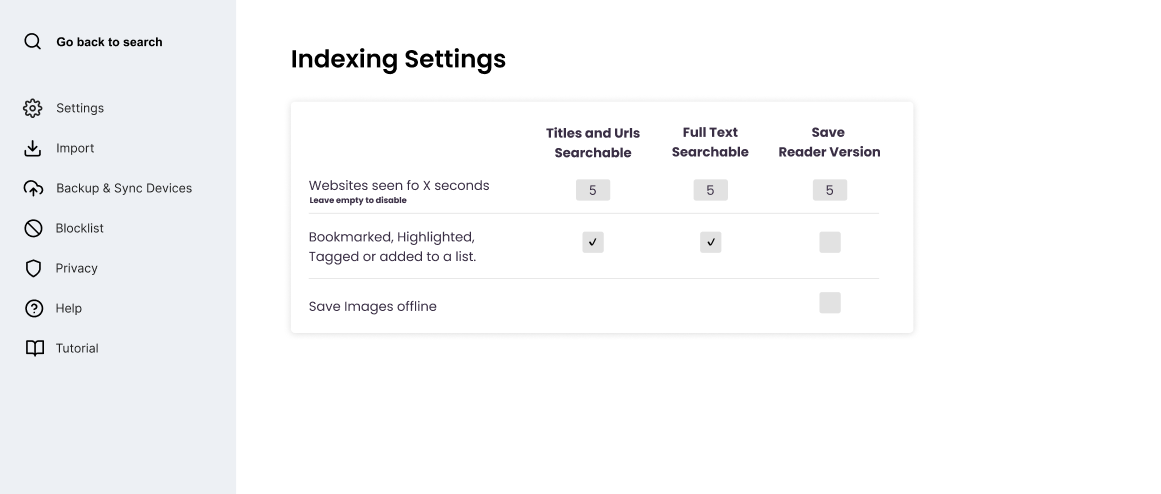
Summary
Being able to make a snapshot of a page to:
- Read it later when offline
- Access the original page when site goes down
- Have Annotations still being anchored, even if site changes
Question to the community:
- What is the reason you’d like to have this feature? What is the workflows you’d like to enable for you?
- How would you like this feature to be implemented?
- What are good examples of other services that do this feature well?
- Which formats for exporting the archives are important to you?