Yes my use case is very similar to @kalmir 's
@BlackForestBoi Thank you, understandable. Here is my more clearly nailed use case. I’ve gone into great detail here so hope I’m not overloading you. Please ask me for clarification or simplification on any of the below points if necessary. Hopefully this is enough detail for @v.denboer
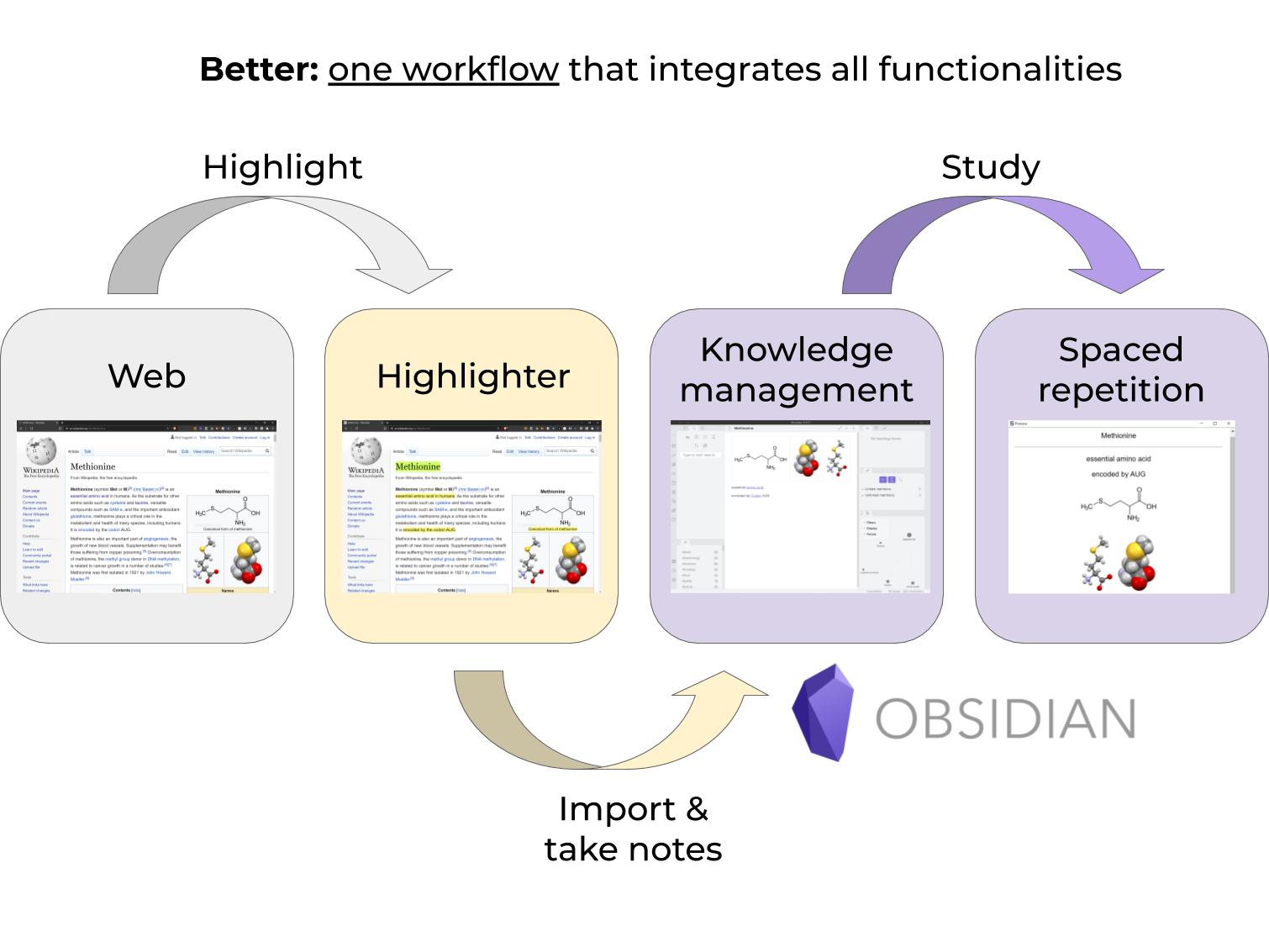
Memex (+ Proposed Xref StorexHub Plugin) - Web Highlights Referencing in Markdown
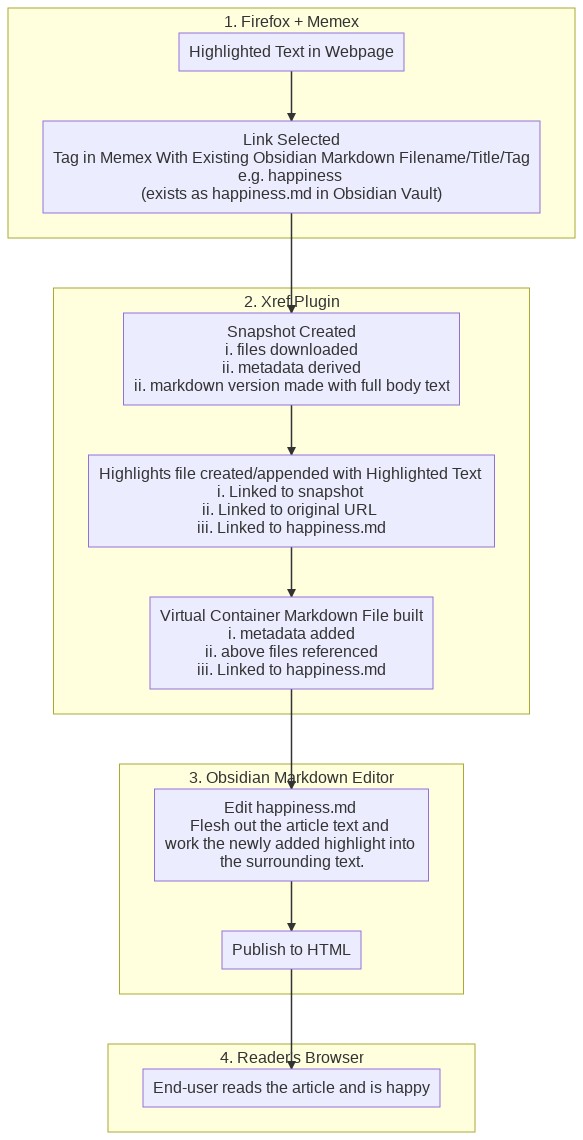
Integrated Workflow Overview
- I highlight some text on a webpage of quotes about happiness and embed it under a specific heading in a markdown article I’m writing (
happiness.md stored in the top level directory of my obsidian vault).
- The Xref Plugin snapshots and derives metadata. It creates markdown files for the highlights and snapshots and links these in the article.
- I later continue work on the article in Obsidian and fit the embedded highlighted quote into the article text.
- The final published article automatically references the author, tags, all other highlights by that author or from that webpage/site, my snapshot of the webpage, my snapshot of the complete HTML of the webpage (snapshots stored in subdirs of obsidian vault), the URL to original webpage.
An example of doing this (the Zettlekasten process) manually for books (or kindle books) is shown by Shu Omi on Youtube using Roam
Detailed Workflow
Memex User Workflow
- I am reading a webpage e.g.
Dalai Llama's Thoughts on Happiness.html
- This sparks a link in my mind to my article I have been writing in Obsidian called
happiness.md
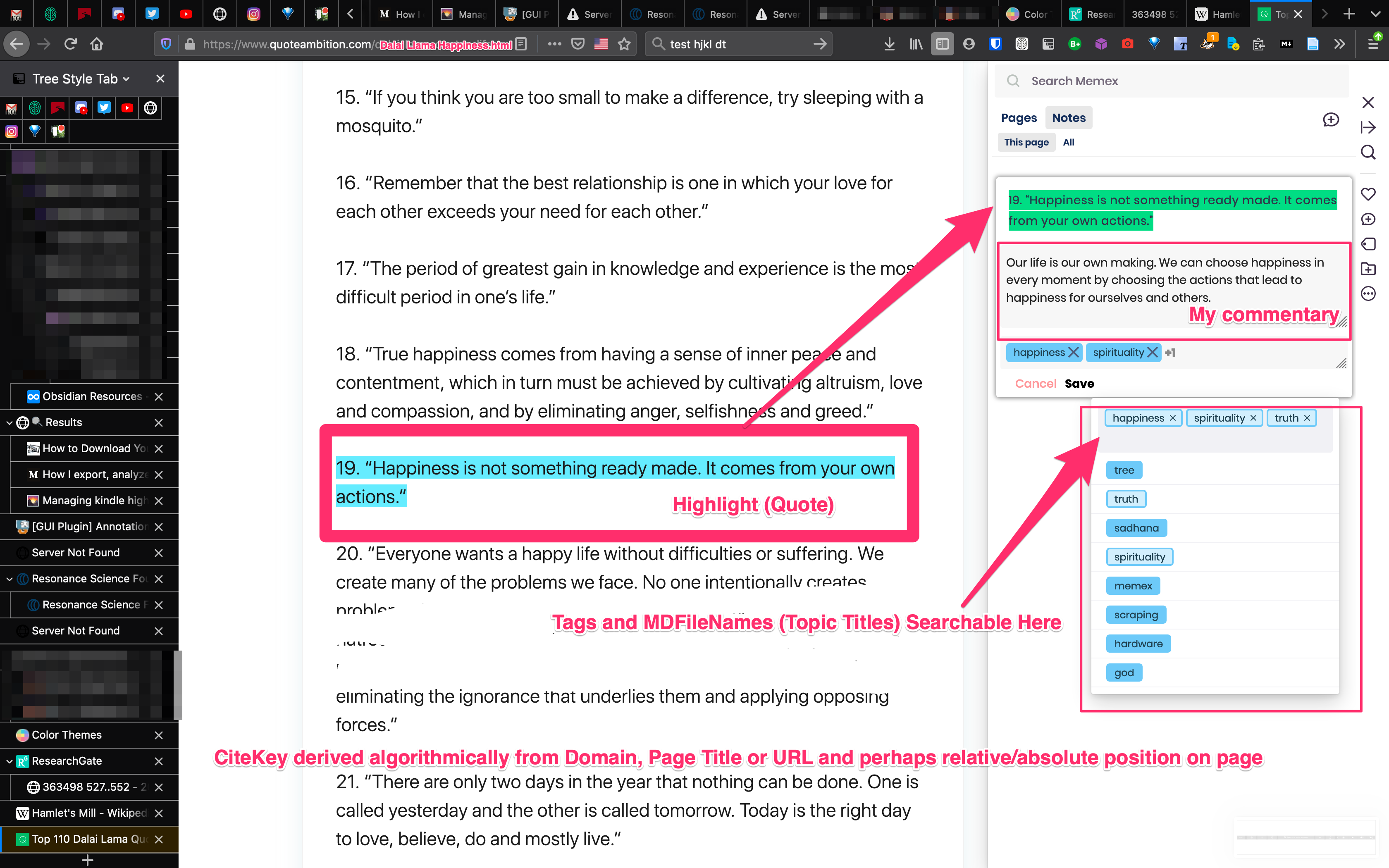
- I highlight a section of the wepage where Dalai Llama says
"Happiness Is not something ready made. It comes from your own actions."
- The memex sidebar tags selector is given focus so I can immediately start typing relevant tags and article titles - in this case
happiness (which is a markdown file) - Optionally followed by the text of the heading where I want the highlight to be embedded (see the explanation of block-level-reference below).
I will always want to tag or reference a markdown file so the annotation menu should always present after every highlight action. There should be no ‘loose’ highlights. At the very least if I don’t tag they should be automatically tagged or linked using pre-set rules e.g. by looking at the text or the tags of the parent page or included in my daily journal log journal/2020-07-25.md Tags/Articles would include the author Dalai Llama, happiness, spirituality. In Obsidian, tags and links are similar, but tags have no file.
Ideally (from the user’s perspective) this entire process could be done from with the browser. So we don’t have to switch back and forth between the webpage we are referencing and the relevant article in Obsidian.
So what I need in Memex is to have the filenames of my markdown folder (called ‘Vault’ in Obsidian), ideally the headings within these files, and all Obsidian tags, synced via my “Xref StorexHub plugin” so that whenever I highlight some text I can immediately start typing one of these within the Memex tags dropdown.
This saves a significant amount of time from the copy and paste workflow which would need context-switch from browser to Obsidian, search for the topic file, find the right place in the file to embed the reference (if I have even fleshed out the structure enough for the right place to fit yet) and then paste the text. With the copy paste model we are limited to referencing only the individual highlights with no way to structure all the other highlights in a linear fashion and link source. If the source is destroyed (which is happening more than you expect, especially for content that contravenes the corporatist agenda e.g. alternative health vaccine etc, search Link rot) the highlight could lose the reference to the author, the context and the related materials.
My ‘Xref’ StorexHub Plugin/App Task
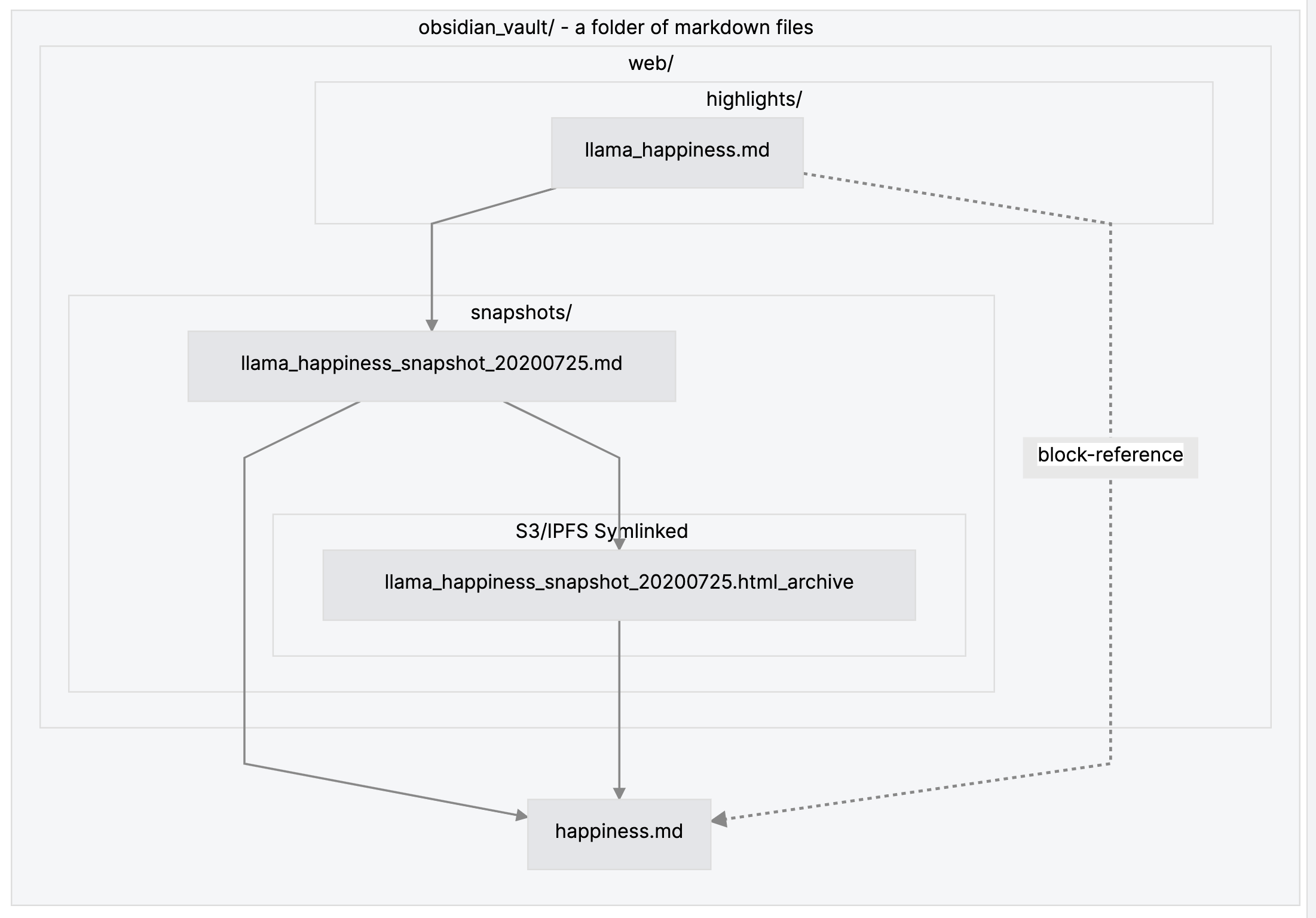
The solid lines represent bi-directional-links with the [[filename]] syntax. The dashed line represents a block-level-embed (a feature implemented by Obsidian) using the syntax ![[filename#heading]]. This allows referencing a specific MD heading (as denoted by the hashtag syntax).
Task Steps
-
Notice via StorexFlow that Memex has saved a new annotation
-
Kick off a snapshot task:
- Snapshot the webpage and all associated media and store
web/snapshots/llama_happiness_20200725.html - I do this using some web-scraping code (in a symlinked folder that is mirrored or partially mirrored to say S3/IPFS e.g. Fleek.co Storage)
- Store the cleaned webpage body text in markdown in
web/snapshots/llama_happiness_20200725.md. Include YAML front-matter with metadata.
- Generate YAML front-matter with metadata (tags, date, title, authors, links to snapshots and original url), insert this at the top of both
snapshots and highlights markdown files.
-
Append to highlights file: the highlighted text with tags under a markdown heading (#) in the format (#citekey @page-position-reference).
-
Append to (or insert at relevant heading) of happiness.md a block-level-reference to said heading of highlights file.
-
The web/highlights/llama_happiness.md references by bi-directional-link the complete bodytext in web/snapshots/llama_happiness_20200725.md which in-turn references a complete HTML snapshot made using python archiver in the same snapshots folder.
Obsidian Workflow
Later on… In Obsidian I continue working on my article that now includes the embedded highlight. My commentary made in the memex annotation is available and I can work the highlight into the article text to make it relevant.
See below for a working example using kindle highlights.
Publishing Workflow
When I publish the article to static HTML using say Gatsby, there is a link in the highlighted quote, to all my highlights on that page (the HTML page generated from web/highlights/llama_happiness.md), my fulltext MD snapshot also generated as a readable HTML, the complete HTML archive snapshot in case the original is down, and the actual original URL. Metadata is available like my link to the author [[Dalai Llama]] which contains further links like the Wikipedia page on Dalai Lllama. Both these pages (internal and Wikipedia links) are viewable directly within the static website article by hovering over the links to see a popover for a short summary + metadata without losing context and having to open another tab, as is done on gwern.net
Why Markdown and Why Obsidian?
I have gone with Obsidian because Roam is inherently broken regarding privacy. Your notes are stored on their Firebase servers in plaintext. Obsidian lets me keep my notes in markdown locally, a much more similar philosophy to that of Memex. Sadly Obsidian is not yet open sourced, I have spoken to the developers but they don’t seem keen on open sourcing the code. For now I have simply blocked all traffic from Obsidian.app and its helper app via a firewall. However, since Markdown is an open format and I can easily port my markdown files to any other editor software like Zettlr. I have written code to easily transform markdown into other formats. Bidirectional links are used by many apps now. So, the only Obsidian specific notation is the block referencing, which may indeed become standard, otherwise I can easily transform that notation to whatever standard format is established with a single line of code.
Markdown Database Model
Lately my use of Markdown files in Obsidian has grown to not only include my notes and articles but a collection of plaintext markdown (MD) files that I am using more as easily accessible source files to derive a powerful graph database.
File Structure
I am using YAML front-matter in all MD files.
In Roam, embeds are more specific as they are using a UID to the database key for each individual block including those below heading level. They are using an in-browser datalog graph db called Datascript, and treat each line as a separate block e.g. - or * in markdown - so actually this is not the complete markdown and is more of an outliner, i.e. there is no way to write a plaintext block without a bullet at the front of it.
Plain Markdown also inherently has a hierarchical structure that could reference below heading level, e.g. individual bullet-points, but we would need a new system that uses IDs to accomodate this.
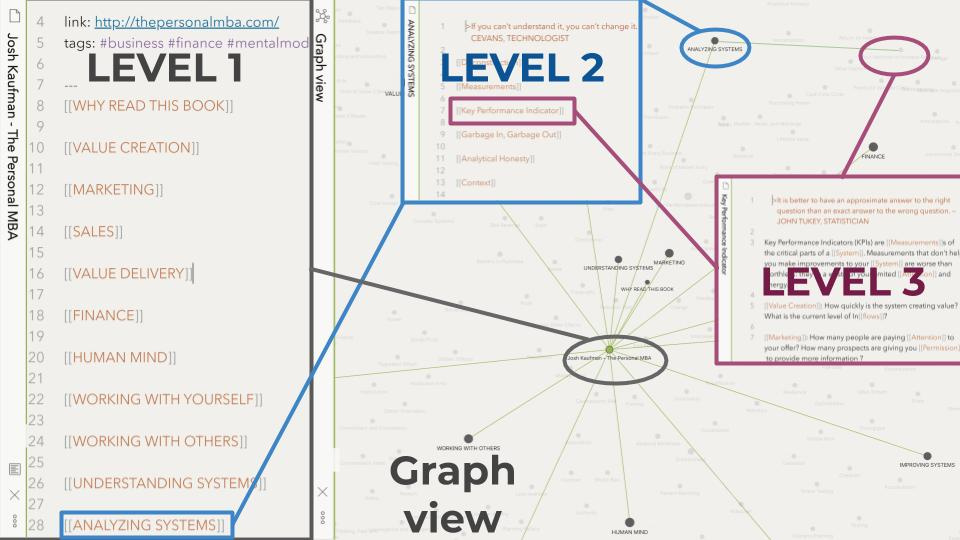
At present everything is working fine with only header level embeds. I have adapted my note format so that the things I need to reference are directly below a single heading with a programmatically generated unique identifier see image below.
Working Example in Obsidian Using Kindle Highlights
Currently, instead of web/, I have implemented this for kindle/ (see below for example) and local pdf/ files that I programmatically scrape. These MD files in the kindle/ and pdf folders contain similar virtual containers which link to the content (PDF or .mobi files) which is snapshotted locally.
The snapshots of the actual media such as webpages, PDF, ebooks, videos, podcasts etc that I am storing locally in symlinked folders that are in .gitignore replicated by duplicity or rsync to an encrypted S3/IPFS or my other computers). This is so my vault doesn’t get too large to fit comfortably in git, but large media files can be easily referenced.
Reference this snapshotted local media, (via the local path and associated S3/IPFS address) within the virtual container MD file along with metadata such as: summary, tags, description. Other related notes can be determined by searching for other MD files with backlinks pointing to this metadata file.
The quotes/highlights (which for a video would be a section of that video) can be referenced in a MD file with my commentary. Either of these (the highlight or my commentary) can be further referenced by block-level-embeds in my final articles, books etc.
In the left pane see the virtual container markdown file that I have programmatically generated by scraping my amazon kindle reader website. In the Web use case, this would the same format as the virtual container for memex website highlights generated by the Xref StorexHub plugin/app i.e. the highlights file.
On the right panes (top is source, bottom is preview) is the article happiness.md, see an example of two quotes I have referenced and embedded in an work-in-progress article about happiness. The block-reference notation is used to directly embed the quote in the article (this inherently contains a link to all this book’s highlights), and the bi-directional-link notation is used to link to my page with commentary about the whole book, and the author, Paramahamsa Yogananda.
The block references are autocompleted in obsidian so it is very easy to reference individual blocks if I know the header (cite-key + @kindle-position-key). cite-key is generated by combining the author year and title in a way similar to Bibtex… I’ve not had any conflicts so far but when it comes to websites (as opposed to books) I’d imagine you’d need to find more intelligent unique keys to reference such as domain, date etc.
Future expansions for multimedia referencing, example using Youtube
- Be able to highlight sections of a Youtube Video by selecting text within the transcript (already possible with Memex, plus the transcript contains timecodes already) or a specific section of the timeline slider.
- The video and full transcript is snapshotted (i already have code to do this), highlighted transcript text is processed exactly like highlighted quotes but the heading is referenced by start-end timecode in. seconds.
- The video is split to take just the highlighted section (I have code for this)