
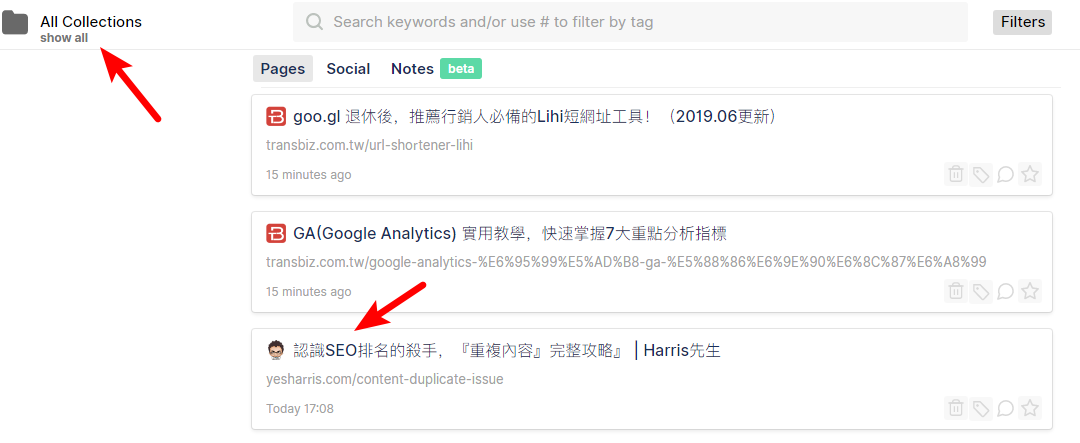
Here’s a newly collected article. Its title and content contain SEO, but I didn’t find this result when I searched SEO in the search box. Please tell me why and how to use it?

Same here. There are no spaces between CJK words, so tokenization by spaces won’t work.
For Korean, even if there are spaces, a particle is attached to the word before it, for Korean is an agglutinative language.
In many languages declensions matter, and it would be convenient if regular expressions were to be allowed.
Some CJK words are searchable tho because indexing is on and the webpage contains the separated word.
And new users can post only one image…
1 Like
CJK does not need word segmentation.
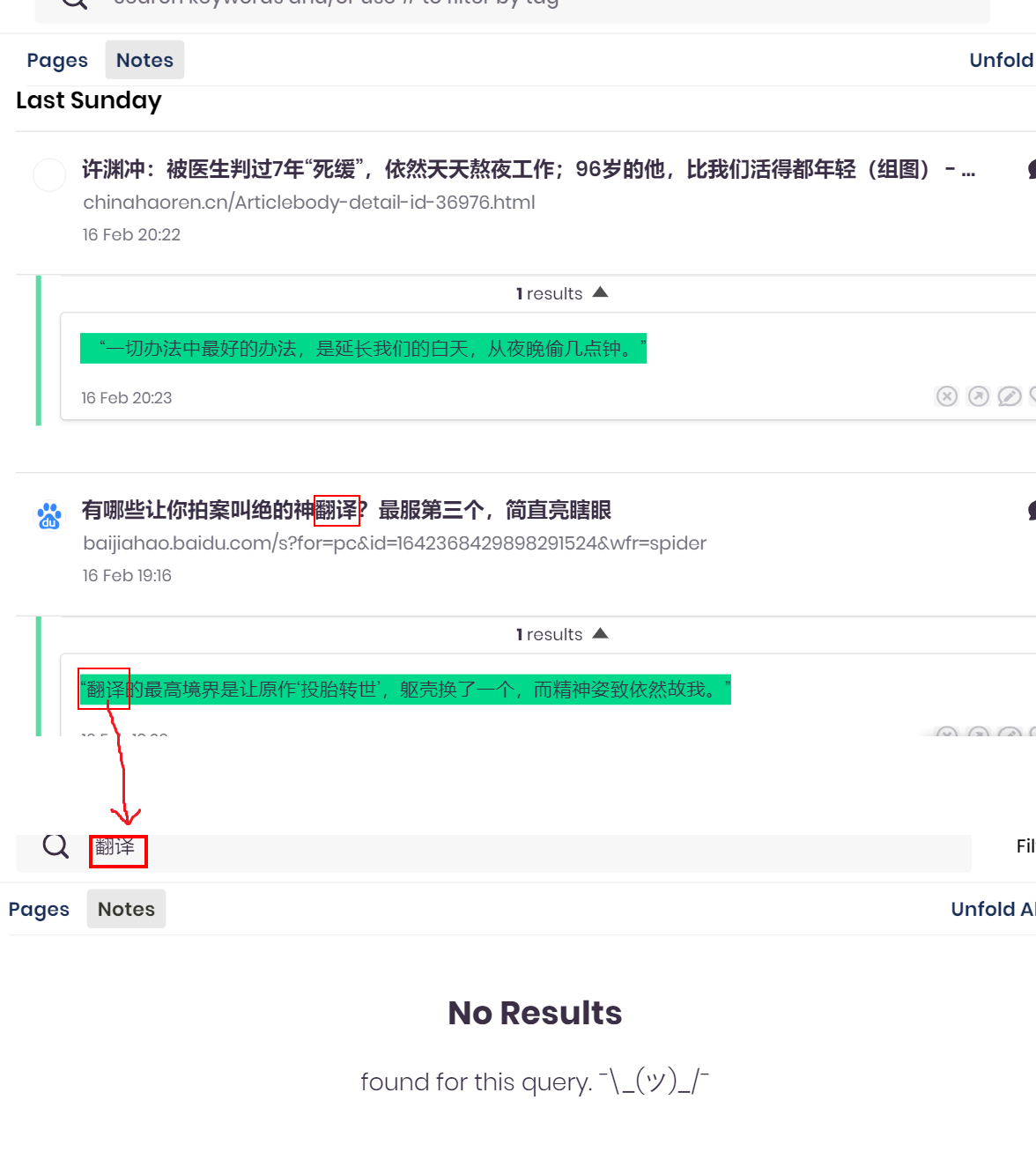
For example, the sentence “你今天看上去不错”, the corresponding English is “You look great today”. In English, we can search for any word in You / look / great / today to find this sentence. But because there are no spaces in Chinese, now we can only search the whole sentence “你今天看上去不错”(equivalent to “You look great today”). In fact, we should be able to find this record by searching for any word in 你/今/天/看/上/去不/错
If someone would be willing to take this one up, that’ll be great.
Shouldn’t be too hard to implement, but we have so many other things competing for our priorities right now 
In any case I think that needs to be optional to users because it will slow down indexing a bit.
Do you know of any fast libraries to detect CJK characters?
Is this helpful?
Glad to hear that, but i don’t have this kind of quick library either.
I think you should check the charset of the webpage first. Some Chinese websites use charset like gb2312 or gbk instead of UTF-8. I guess Japanese and Korean websites are similar. From these character sets, it can be judged that the page must use CJK, and the cost of this detection is also minimal.
If it is a UTF-8 page that uses CJK, then you can only use regular expressions to detect. The costs may be relatively large, you may need a switch. One way is to randomly detect the text on the page and let users choose the upper limit of detection, such as 20. Each time a word in the web page is checked to see if it is a CJK character. If it is, stop the detection. And mark the website as a CJK website. If not, continue testing until the upper limit is reached.
If you find that a page is a CJK page, the faster method is to detect whether the characters are English or numbers, and all other types of characters are treated as CJK. After all, web pages with both CJK and other non-English characters are quite rare. At least I have never seen it
1 Like
Or as @BlackForestBoi mentioned before, people could set their own default indexing method. And IMO it would be great if people could temporarily enable / disable it at the sidebar for each page. Besides, the engine could simply detect whether there are CJK chars in the title since I think it’s rare for a CJK page only contains English chars in the title (and if that’s an eng-based page using a few CJK chars, the CJK chars may already indexed properly).
Please support CJK character, I can’t search for anything in Traditional Chinese.
I just dropped from a similar service called Liner because they don’t CJK character.